
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- String Constants Pool
- docker mongodb
- jvm memory model
- JPA
- Constants pool
- springboot mongodb config
- springboot jwt example
- 기본 Manifest 속성이 없습니다
- HHH000104
- mongodb install ec2
- jwt token
- intern
- install mongodb docker
- jpa pagination
- jvm memory structure
- spring jwt
- JWT
- springboot-angular-jwt
- angular jwt
- springboot maven plugin
- jvm 모델
- string comparison
- String Pool
- jwt example
- spring filter ordering
- docker mongodb install
- springboot jwt
- filter ordering
- jvm 메모리 구조
- spring-boot-maven-plugin
- Today
- Total
개발블로그
fetch join with pagination :: [HHH000104: firstResult/maxResults specified with collection fetch; applying in memory] 에러 해결 본문
fetch join with pagination :: [HHH000104: firstResult/maxResults specified with collection fetch; applying in memory] 에러 해결
개발자수니 2021. 1. 9. 02:58결론은 1:N 관계에서 fetch join과 pagination은 동시에 할 수 없다. 따라서 pagination을 한 뒤, fetch하여 조합하는 방법을 택했다.
요구사항과 문제는 다음과 같았다.
- 어드민 화면을 구성하는데, A,B,C,D Table에 있는 컬럼들을 기준으로 검색과 페이징이 가능해야 했다.
- 예를 들어, 검색 필드에 "이름" 이 있다. 이름 필드에 값이 들어오면(null이 아니면) 이름은 where 절에 포함되어야한다. 하지만 이름 값이 null로 들어오면 where절에 포함되지 말아야한다.
- 그리고 위와 같은 검색 필드는 A,B,C,D table 각각에 1개 이상씩 존재한다.
- 검색 결과 응답 컬럼은 A,B,C,D,E,F Table에 있는 컬럼들이었다.
- 엔티티의 관계
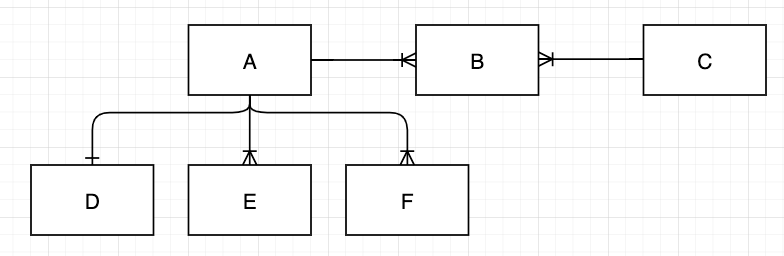
관계의 중심은 A였고, 검색 결과 A의 개수에 따른 페이징이 필요했기 때문에 A 테이블을 베이스로 쿼리를 작성했다.
쿼리 생성은 JPQL을 이용했다.
JPQL을 이용해 Pagination하는 방법은 Baeldung 을 참고하면 된다.
간략하게 얘기하면 entityManager의 createQuery funtion을 이용해 Query 객체를 만든다.
그리고 그 Query 객체에 firstResult, maxResults을 세팅해주면 hibernate에서 pagination query를 만들어준다.
애초에 Fetch Join이 필요했던 이유와 Pagination + Fetch Join을 했을 때의 문제점을 살펴보자.
1) Fetch Join을 하지 않고, Pagination만 했을 때의 문제점
@Language("HQL")
private fun buildJPQL(request: SearchRequest, sort: Sort): String {
return """
SELECT a
FROM A a
INNER JOIN a.bs b
INNER JOIN b.cs c
INNER JOIN a.ds d
LEFT OUTER JOIN a.es e
LEFT OUTER JOIN a.fs f
WHERE 1 = 1
${if (request.condition1 != null) "and b.xxx = ${request.condition1}" else ""}
${if (request.condition2 != null) "and a.xxx = ${request.condition2}" else ""}
${if (request.condition3 != null) "and c.xxx = '${request.condition3}'" else ""}
${if (request.condition4 != null) "and d.xxx = '${request.condition4}'" else ""}
//order문 생략
"""
}
4라인: 쿼리의 반환값으로 A entity를 받도록 했다.
실행되는 쿼리를 살펴보면 문제가 없으나 A entity와 1:N 관계를 가지고 있는 B entity를 A entity를 통해 호출할 때 다음과 같은 에러를 만날 것이다.
LazyInitializationException: could not initialize proxy - no session
이는 B entity가 jpa cache에 로드되지 않았음을 의미한다. 로드를 시키기 위해서는 Fetch Join을 해줘야한다.
응답 요구사항 컬럼이 A,B,C,D,E,F entity에 모두 속해있으므로 모두 Fetch 해야했다.
2) Pagination + Fetch Join 시 문제점
@Language("HQL")
private fun buildJPQL(request: SearchRequest, sort: Sort): String {
val fetchQuery = "${if (isCountQuery) "" else "FETCH"}"
return """
SELECT a}
FROM A a
INNER JOIN $fetchQuery a.bs b
INNER JOIN $fetchQuery b.cs c
INNER JOIN $fetchQuery a.ds d
LEFT OUTER JOIN $fetchQuery a.es e
LEFT OUTER JOIN $fetchQuery a.fs f
WHERE 1 = 1
${if (request.condition1 != null) "and b.xxx = ${request.condition1}" else ""}
${if (request.condition2 != null) "and a.xxx = ${request.condition2}" else ""}
${if (request.condition3 != null) "and c.xxx = '${request.condition3}'" else ""}
${if (request.condition4 != null) "and d.xxx = '${request.condition4}'" else ""}
//order문 생략
"""
}3라인, 7~11라인: 카운트 쿼리 여부에 따라 FETCH JOIN을 하도록 했음을 알 수 있다.
이를 실행시키면 에러는 나지 않고, 터미널에 WARN 로그가 찍혀 있는걸 볼 수 있다.
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory
그리고 실행된 쿼리를 자세히 보면 마지막에 limit 문이 없을 것이다. 즉 조회된 결과를 모두 다 가져오는 것이다.
이유는 1:N 관계를 fetch join하게 되면, 몇 개의 row까지 가지고 와야하는지 예측할 수 없어서 firstResult, maxResults 설정 값이 무시되기 때문이다. 그리고 limit 을 두지 않고 조회한 결과를 모두 java memory에 올려놓고 pagination을 위한 계산을 한다.
데이터가 별로 없으면 정상적으로 동작하는 것 처럼 보여 간과할 수 있다. 하지만 이대로 운영환경에 올린다면, 언젠가는 memory leak이 발생할 것이다. (사실, 본인이 경험한 일이다..)
3) 해결
구글링을 했을 때, 연관관계를 바꾸는 해결법이 많이 제시되었지만, 나의 경우는 A 엔티티가 여러 엔티티와 1:N 관계를 가졌기에 그럴 수 없었다.
그럼에도 검색조건을 필터링한 Pagination과 Fetch Join 모두 필요한 나로서는 쿼리를 두번 날리는 방법을 택했다.
첫 번째는 검색 결과를 필터링 한 Pagination된 A엔티티의 id값들만 받아오는 것이다. 선택한 size만큼의 id 개수가 반환될 것이다.
그리고 그 id들로 Fetch Join한 List<A>들을 받아온다.
@Language("HQL")
private fun buildJPQL(request: SearchRequest, sort: Sort): String {
return """
SELECT distinct a.id
FROM A a
INNER JOIN a.bs b
INNER JOIN b.cs c
INNER JOIN a.ds d
WHERE 1 = 1
${if (request.condition1 != null) "and b.xxx = ${request.condition1}" else ""}
${if (request.condition2 != null) "and a.xxx = ${request.condition2}" else ""}
${if (request.condition3 != null) "and c.xxx = '${request.condition3}'" else ""}
${if (request.condition4 != null) "and d.xxx = '${request.condition4}'" else ""}
//order문 생략
"""
}4라인: 따라서 반환 값은 a.id 뿐이다.
앞선 코드들과 달리 E,F 엔티티와 LEFT OUTER JOIN하는 코드를 제거했다. E,F는 검색할 때 필요한게 아니라 Fetch 하기 위해 필요한 엔티티였기 때문이다.
위 쿼리로 Pagination 결과를 받아, Fetch 결과와 조합하여,
val pagedAIds = this.search(request) //jpql pagination
val fetchedA = aRepository.findByIdIn(pagedAdSetIds).associateBy { it.id } //fetch join 조회
pagedAIds.map { fetchedA.getValue(it) } //결과원하는 결과를 얻을 수 있었다.
'Spring' 카테고리의 다른 글
| HHH000502 warning :: entity was modified, but it won't be updated because the property is immutable. 원인 해결 (0) | 2021.06.26 |
|---|---|
| ParameterDataTypeReader : Trying to infer dataType Warning 해결 (0) | 2021.05.25 |
| spring cloud api-gateway 사용하기 (0) | 2019.12.24 |
| spring-boot-maven-plugin (기본 manifest 속성이 없습니다 오류 해결) (0) | 2019.09.06 |
| Filter Exception 처리 (0) | 2019.08.22 |

